Folge mir auf LinkedIn, um Teil meiner Journey zu sein | Shaping transformation of occupational medicine and digital health | #digitalhealth, #digitalhealthcare, #arbeitsmedizin, #innovation, #neverstoplearning | Institutsleiter [Chefarzt] | Leitender Facharzt für Arbeitsmedizin mit Industrie- und Führungserfahrung, Chief Medical Information Officer (CMIO) für Datenmanagement im Arbeits- und Gesundheitsschutz, Master of Health Business Administration [MHBA], PowerMBA (ExecutiveMBA) [ThePower Business School], Weiterbilder und Weiterbildungsbefugter für Facharztkompetenz Arbeitsmedizin (Umfang: 36 Monate) sowie Zusatzbezeichnung Betriebsmedizin (9 Monate Weiterbildungsbefugnis), Ärztliches Qualitätsmanagement, Arbeitsschutzmanagementsystembeauftragter (MAAS-BGW, BGW qu.int.as), Interkulturelle Kompetenz für den Arbeitsschutz (Integrationsmanagement), Anästhesist, Notfallmedizin, Medizininformatiker, Gesundheitsökonom, Ermächtigung zur Durchführung der ärztlichen Überwachung beruflich exponierter Personen nach § 175 Abs. 1 Strahlenschutzverordnung (StrlSchV), Fachkunde nach § 47 Abs. 1 Strahlenschutzverordnung, Berater bei agiler Softwareentwicklung/Consultant, Führungskraft/Leader und Coach, Keynote Speaker, Digital Health Expert/Advisor/Berater und Enthusiast, Stratege, Vordenker, Innovator, Prozessoptimierer und Transformator, ehemals Leiter und Moderator von Führungskräftewerkstätten inklusive kollegialer Beratung, ehemaliger Leiter Steuerungskreis für Betriebliches Gesundheitsmanagement (BGM), Autor, Dozent, Visionär, Data Science: Natural Language Processing und Image Segmentation mit Python, Scrum Master, Product Owner, Team Kanban Practitioner (TKP), Agile Coach, Lean Six Sigma Green Belt, Design Thinking Professional, DevOps, OKR Master Certified Professional, OKR Champion, Qualitätsmanager, Certified ISO/IEC 27001 Internal Auditor, Certified ISO 22301 Internal Auditor for Business Continuity Management (BCM), Qualitätszirkel-Moderator, Innovation Management Certified Professional, Reisemediziner, DTG-Zertifikate Reisemedizin und Arbeitsaufenthalt in den Tropen, ehemalige Gelbfieberimpfstelle, Zusatzbezeichnung Suchtmedizinische Grundversorgung, Psychosomatische Grundversorgung für Arbeits- und Betriebsmediziner, ehrenamtlicher Digitaler Ersthelfer im Cyber-Sicherheitsnetzwerk (Bundesamt für Sicherheit in der Informationstechnik [BSI]), Brandschutzhelfer, Brückenbauer sowie "Dolmetscher" zwischen Fachdisziplinen und Stakeholdern
Data Science: Natural Language Processing mit Python
If you can’t explain it simply, you don’t understand it well enough.
Albert Einstein
Data Science ist ein multidisziplinäres Feld, das statistische, mathematische, analytische und programmatische Fähigkeiten nutzt, um Erkenntnisse und Wissen aus großen Datenmengen zu gewinnen. Es kombiniert verschiedene Techniken und Ansätze aus den Bereichen Statistik, Informatik, maschinelles Lernen und Datenvisualisierung, um Daten zu sammeln, zu organisieren, zu analysieren und daraus Schlussfolgerungen zu ziehen.
Der Prozess der Data Science umfasst in der Regel mehrere Schritte:
Datenerfassung: Daten werden aus verschiedenen Quellen gesammelt, wie z.B. Unternehmensdatenbanken, öffentlich zugänglichen Datenbanken, sozialen Medien oder IoT-Geräten. Die Daten können strukturiert (z.B. Tabellenformat) oder unstrukturiert (z.B. Text, Bilder) sein.
Datenbereinigung und -integration: Die gesammelten Daten werden bereinigt, um Fehler, Ausreißer und fehlende Werte zu entfernen. Zudem werden verschiedene Datenquellen integriert, um eine einheitliche Datenbasis zu schaffen.
Datenexploration und -visualisierung: Die Daten werden untersucht, um Muster, Trends und Zusammenhänge zu identifizieren. Dies erfolgt durch statistische Analysen und Visualisierungstechniken, um die Daten auf anschauliche Weise darzustellen.
Modellierung und Vorhersage: Mit Hilfe von Algorithmen und statistischen Modellen werden Zusammenhänge zwischen den Daten identifiziert und Vorhersagen oder Mustererkennungen getroffen. Hier kommen Techniken des maschinellen Lernens und der künstlichen Intelligenz zum Einsatz.
Kommunikation der Ergebnisse: Die gewonnenen Erkenntnisse werden in verständlicher Form präsentiert, um Entscheidungsträgern oder anderen Interessengruppen bei der Entscheidungsfindung zu unterstützen. Dies kann in Form von Berichten, Visualisierungen oder interaktiven Dashboards erfolgen.
Data Science findet in einer Vielzahl von Gebieten Verwendung, wie z.B. Wirtschaft, Finanzen, Gesundheitswesen, Marketing, Sozialwissenschaften und vielen anderen. Durch die Nutzung großer Datenmengen und fortschrittlicher Analysetechniken ermöglicht Data Science Unternehmen und Organisationen, bessere Einblicke in ihre Daten zu gewinnen, fundierte Entscheidungen zu treffen, Prozesse zu optimieren, Muster und Trends zu erkennen sowie Vorhersagen zu treffen.
Impressionen zu exemplarisch durchgeführten Analysen
Linguistische Analyse
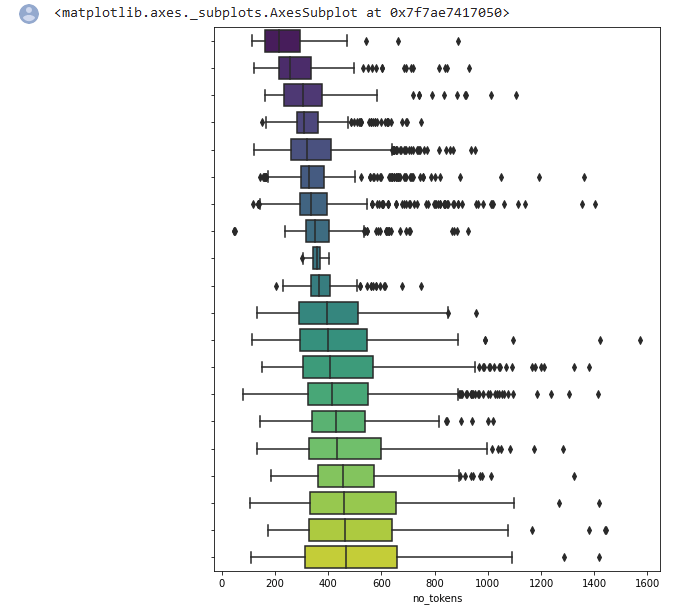
Text- und Metainformationen
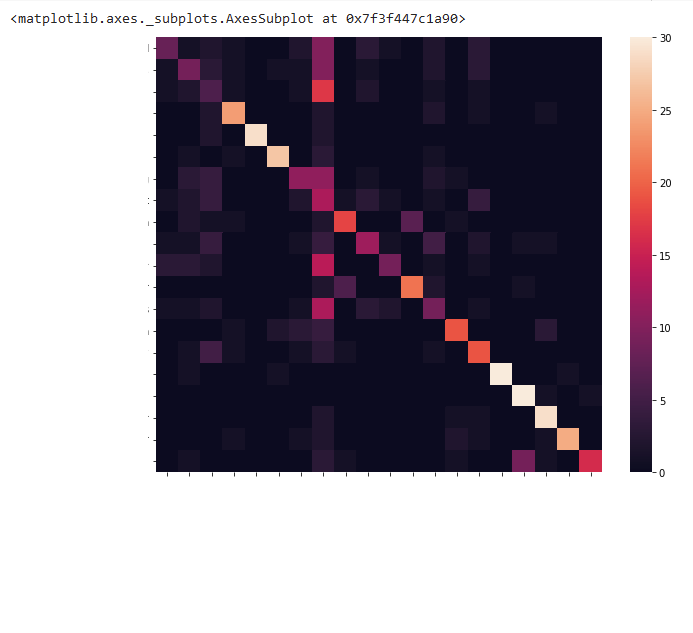
Confusion Matrix
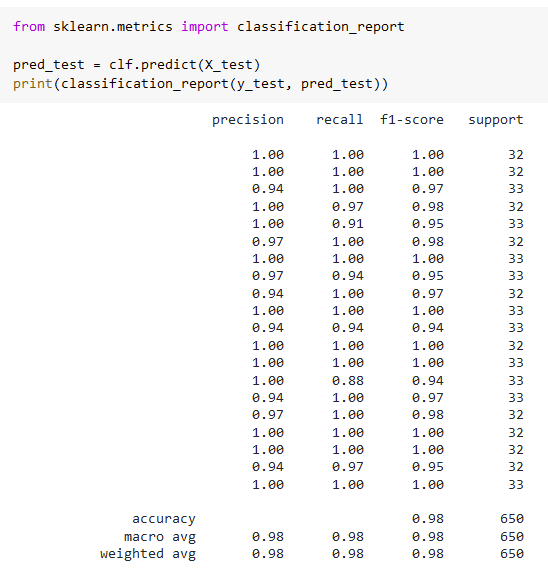
Vorhersage mit ML-Modell: Classification Report
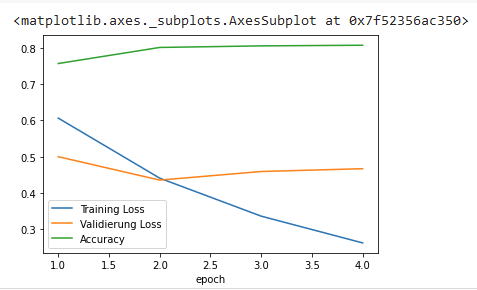
BERT-Klassifikation: Ergebnisse
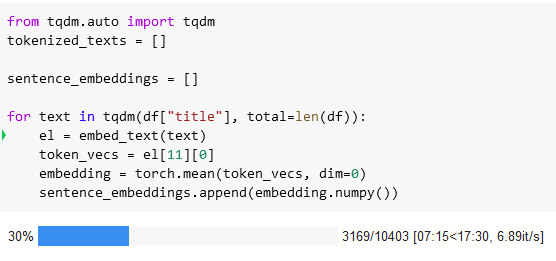
Embeddings
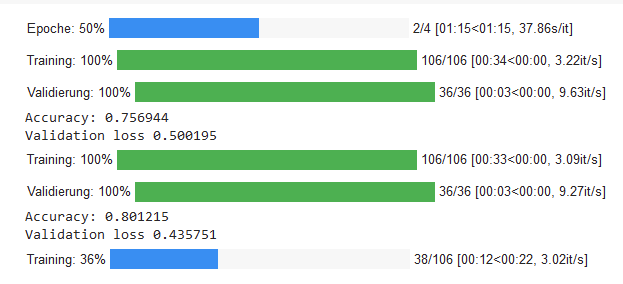
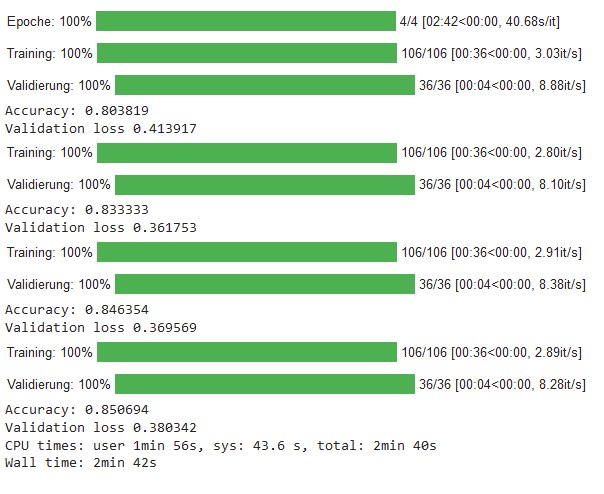
BERT-Klassifikation: Prozess Part 1
BERT-Klassifikation: Prozess Part 2
Cookies 🍪: Man kann sie zwar nicht essen, aber sie verbessern den Genuss der Seite. Warum bekomme ich den ganzen Tag Cookies, die ich akzeptiere? Um diese Website für Sie optimal zu gestalten und fortlaufend verbessern zu können, werden Cookies verwendet. Durch die weitere Nutzung der Website stimmen Sie der Verwendung von Cookies zu. Weitere Informationen zu Cookies erhalten Sie in der Datenschutzerklärung.